Today I released ppbert 0.8.4 after I read a comment
on Hacker News that made me leap out of my chair: buffering StdoutLock improves the performance
of IO-bound programs! Previously, I thought that doing stdout.lock() was sufficient. Oops!
This release also marks the first time that one of my original test files can be pretty printed in less than a second. I’ll use this occasion to look back on ppbert and how I was able to improve its performance, little by little.
As I mentioned in a previous post, I created ppbert because I needed a tool to inspect the content of the .bert files we use in production, and Erlang was just too slow for that purpose. There were two files that were of particular interest to me; in this post, I’ll just call them FileA and FileB.
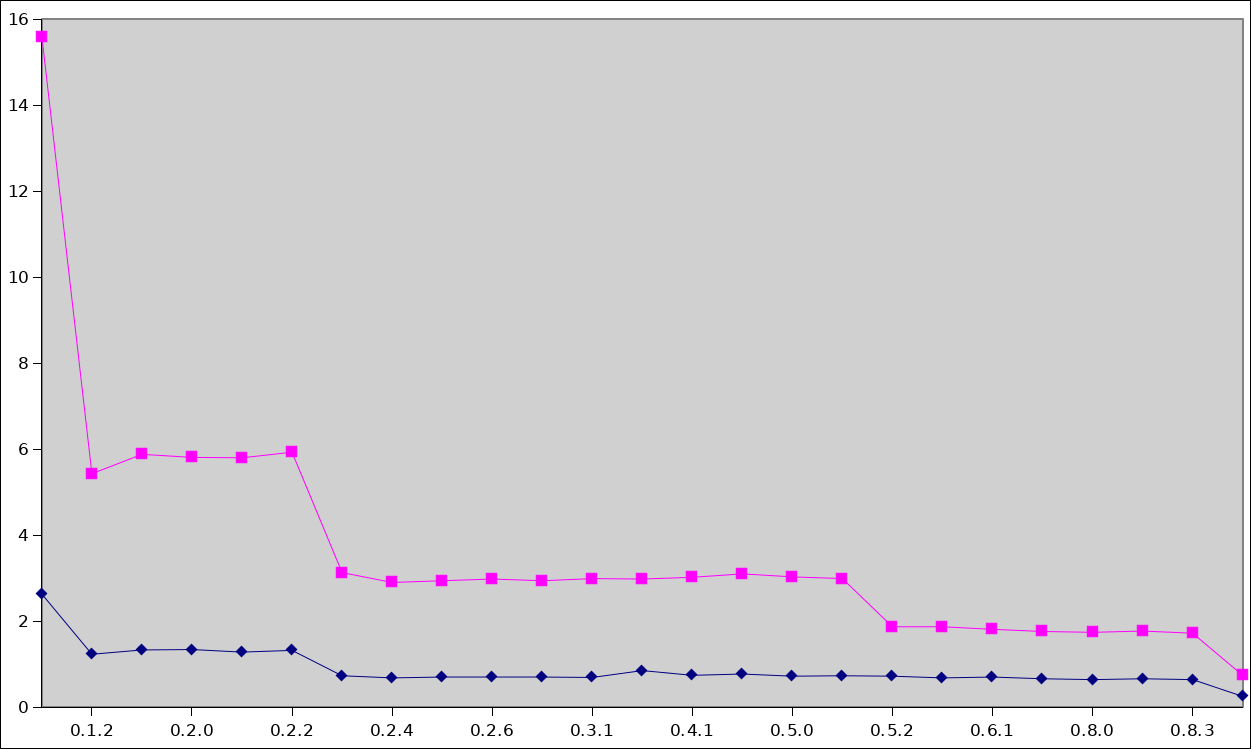
- FileA is 11 MiB in size, and is the most important .bert file in our production system. If something seems off, it is the first place where I want to go look. On my laptop, Erlang takes 9 secs to parse and pretty print FileA.
- FileB is 96 MiB in size and it was the largest file .bert file we had at the time. On my laptop, Erlang takes 50 secs to parse and pretty print FileB.
Pre-historic times: nom
Every quarter at work, we reserve one Friday to work on open source projects.
I started ppbert during one of those Open Source Fridays, and I used nom to get moving quickly.
By the end of the day, I had my first working prototype, and I was very excited:
my new prototype was faster than Erlang!
I don’t have time measurements from back then; my current laptop processes FileA in 2.63 secs and FileB in 15.60 secs.
Over time, though, I grew disenchanted with nom.
I had difficulty using its macros, and it was difficult to have my own custom errors, so I decided to write my own parser.
(N.B.: this was with nom 2; I have not tried nom 3.)
The first tagged releases
After a bit of work on my own hand-written parser — not very hard and surprisingly fun for me — I was able to parse and pretty-print again. This is when I started turning my attention to performance. I was happy that I was faster than Erlang, and I was already using ppbert daily at work. Still, I thought it should be possible with Rust to improve the performance of ppbert further. I thought that might make the tool more useful to me and others. (I strongly believe that performance is an enabler: if something is fast enough, people use it more, and they can often use it in new and surprising ways.)
The first tagged release of ppbert, 0.1.2 in April of 2017, took 1.26 secs to process FileA and 5.42 secs for FileB.
Before, I was printing directly to stdout; in 0.1.2, I decided to implement the Display
trait for my AST, BertTerm.
I was really happy that writing to an in-memory buffer had such a noticeable impact on performance!
The next performance improvement came 3 weeks later, ahead of the 0.2.3 release.
I noticed that I was computing the indentation string (i.e., a string made of white spaces)
for every element of a list or a tuple.
I moved this computation outside of the loop, along with a few other minor changes
(e.g., using .write_str() and .write_char() instead of write!("{}", expr) when
approriate).
The time to process FileA and FileB were now 0.7 secs and 3.0 secs respectively.
In June and July, I toyed around with a few micro-optimizations.
If an atom contained only ASCII characters, I skipped the latin-1
validation and called the unsafe String::from_utf8_unchecked() function.
I also reserved the right amount of memory for the buffers for Strings and Binaries.
Together, these small optimizations brought the times down to 0.69 secs and
2.88 secs.
At that point, I was happy with performance, and concentrated mostly on features: adding support for JSON output, IMO one of the best feature of ppbert when combined with the amazing jq; supporting our new .bert2 format at work; a new command-line tool to convert between .bert and .bert2; improving the user interface; cleaning up the internals; etc.
Eight months pass
I kept using ppbert daily, and I was really happy with it.
Eventually, I got back to trying to find places where I could improve performance.
In ppbert 0.5.2, released in April 2018, I found that it was faster to write my
String and Binary literals into a String buffer and send that entire buffer to
.write_str().
The time to process FileA stayed pretty much the same at 0.65 secs, an improvement of 40 milli-seconds.
However, for FileB, which is larger, the optimization reduced the time needed to pretty print it to 1.77 seconds, a one second improvement!
The 0.6.1 release was interesting: I managed to remove a bunch of unsafe blocks
that I had put in for “performance reasons”, but without affecting the overall performance.
And that’s where performance had been, until today, when I added this simple line:
let mut stdout = BufWriter::new(stdout);
Now, ppbert can process FileA in 0.25 secs and FileB in 0.75 secs. I’m really happy with the progress that I made and with the way I made progress: by finding little places where I could improve performance, and slowly making ppbert faster and faster.
Here is a small chart showing the evolution of ppbert’s performance on FileA and FileB:
Thanks to Richard Kallos for proof-reading this article.